It started on a Monday. Alarms were blaring, and our data ingestion queues were overflowing. In a short span of time, our connected battery fleet had grown from 100 to over 1,000 units, and the FlexiTwin platform we had built with pride was now on the verge of complete collapse.
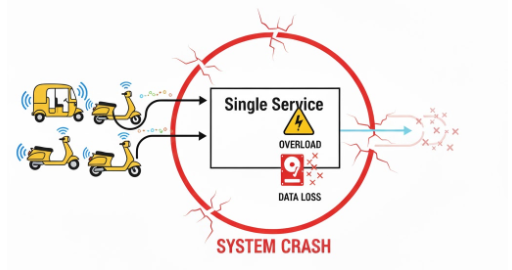
We were facing every startup's best and worst nightmare: our growth was outpacing our infrastructure. Data was being lost, customers were impacted, and the service that was central to our business was buckling under the pressure.
This isn't just a story about data. It's the story of how we confronted a tsunami of data velocity and re-architected our system from the ground up to be resilient.
The Day the Data Tsunami Hit
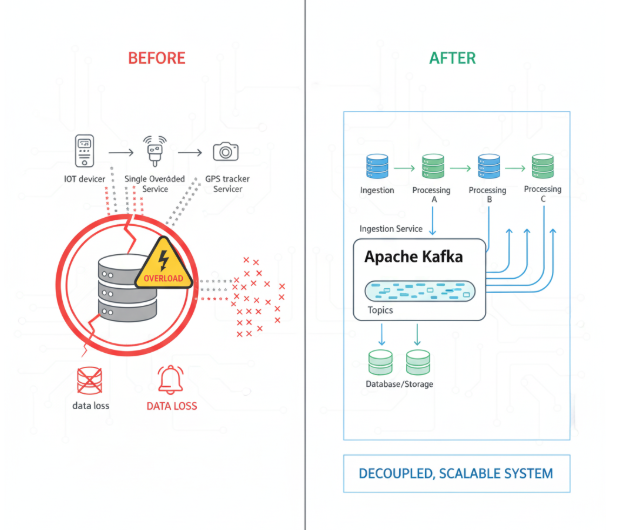
In the early days, our system was simple and it worked. A single service handled everything—receiving data from our FlexiPack batteries, processing it, and storing it.
Our old system was like a restaurant with only one employee. He had to greet customers, take their orders, cook the food, and wash the dishes. When you only have a few tables, that works just fine.
But as our company grew, we didn't just get more customers—we got a busload of them arriving all at once. For us, that "busload" was onboarding multiple new batteries in a single day, doubling our system's load overnight.
Suddenly, our one-man-band restaurant couldn't cope. The employee was so busy taking orders (ingesting data) that he couldn't cook the food (process the data). Orders got lost, the kitchen backed up, and the whole restaurant ground to a halt. In technical terms, our ingestion and processing were tightly coupled, making the entire system brittle.
Our Secret Weapon: A Digital Assembly Line
We realized our problem wasn't just volume, but velocity—the sheer speed at which data was hitting us. The solution wasn't to make our single employee work faster; it was to build a proper kitchen assembly line.
At the heart of our new design is Apache Kafka. Think of Kafka as the digital equivalent of a restaurant's order rail.
- The Host (Ingestion Layer): We built a lightweight service whose only job is to greet incoming data, validate it, and instantly place it on the Kafka "order rail." It's fast, efficient, and never gets blocked.
- The Chefs (Processing Layer): A separate team of services acts as our "chefs." They can pick up the data "orders" from the rail whenever they have the capacity, process them, and send them to our storage systems.
This "decoupled" approach means a rush at the front door never overwhelms the kitchen. Each part of the system can scale independently. If we get another busload of data, we can just add more hosts or partition our order rail further, without ever slowing down the chefs.
From Surviving to Thriving: Our New Reality
After re-architecting, the change was night and day. The alarms stopped, the data loss went to zero, and our platform became the resilient backbone we always knew it could be.
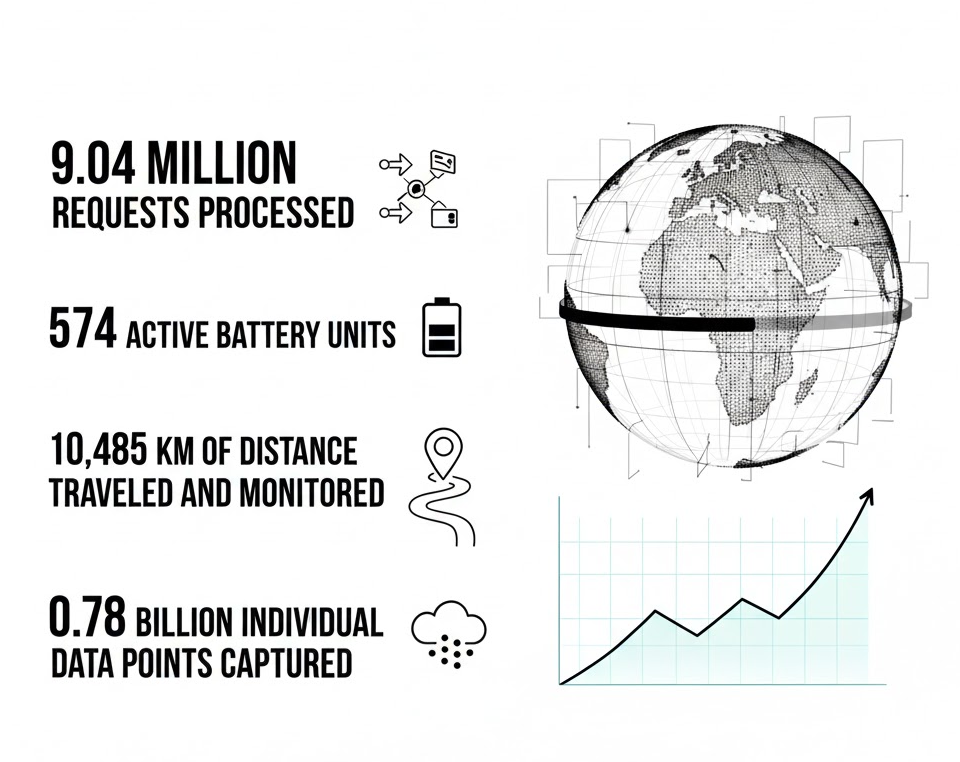
Today, FlexiTwin processes roughly 80 requests every single second—continuously, with zero data loss and minimal latency. Here's a snapshot of what a single day looks like now:
Our 3 Scaling Commandments
This journey taught us a few brutally honest lessons that are now core to our engineering philosophy.
Speed can break you faster than size. Design for bursts, not just averages.
Your system is only as strong as its most brittle connection. Independent services are the foundation of resilience.
We built extensive monitoring to watch every part of our new assembly line. Obsess over observability from day one.
What's Next?
Scaling isn't a one-time event—it's an ongoing discipline. With this new foundation, we're excited to tackle the next phase: building real-time anomaly detection, optimizing our time-series storage, and delivering the predictive insights that will define the future of energy systems.
We're just getting started.